ラベリングがセグメンテーションの妨げになるのを避ける方法
ゼロトラスト は、組織のセキュリティに対する考え方を変えました。歴史的に、私たちは「悪い」ものをすべて特定し、それをブロックしようとしていました。しかし、ゼロトラストアプローチとは、通信元を検証し、それを許可することで、何が「良い」かを特定することです。
ゼロトラストを実現するには、次のことを行う必要があります。
- 信頼できるエンティティの ID を特定して管理します。
- ゼロトラストセグメンテーションを使用して、そのIDに適用されるポリシーを適用します。
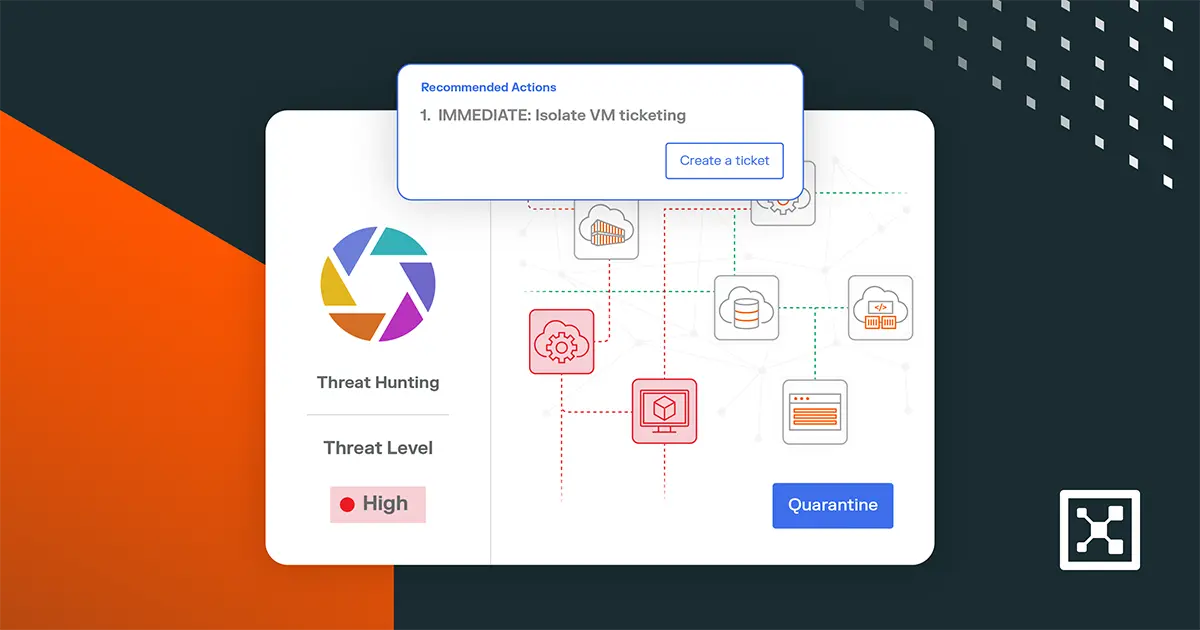
しかし、 ゼロトラストセグメンテーション の実装とポリシーの適用において認識されている課題の1つは、ネットワーク上のすべてのエンティティの知識がどれだけ完全であるかということです。
イルミオが委託した 最近の調査 では、回答者の19%が、完璧なデータがないためゼロトラストを実装できないと回答しました。
イルミオのゼロトラスト仮想ワークショップシリーズの参加者も同様の懸念を表明し、ゼロトラストに苦労しているのは次のものが欠如していることを強調した。
- システムに関する正確な情報。
- 存在するサーバーまたはワークロードに関する知識。
- どのアプリケーションがどのリソースに接続されているかを理解する。
多くの組織では、構成管理データベース(CMDB)、IPアドレス管理システム、クラウドタグ、スプレッドシート、または同様のリポジトリシステムが、この情報の「信頼できる情報源」となるのが理想的です。ただし、これらの情報リポジトリ システムは不正確であるか、まったく存在しない可能性があります。
存在する情報を使用して、構造化されたラベル付けモデルを構築できることが重要です。それがないと、環境はこのようになるからです。

CMDBはラベリングのすべてではありません
組織が直面する主な問題の 1 つは、衛生面の命名です。システムが進化し、人事が異動するにつれて、命名規則も変化します。
たとえば、「Production」で始まるものが「Prod」になり、次に「prod」になります。つまり、ゼロトラストポリシーを適用するルールは、最初に書き込まれたときから名前が変更されるまで廃止される可能性があります。
ラベル付けのフリー テキスト スタイルは、ルールの作成に多くの不整合を引き起こす可能性もあります。リソースのラベル付けが不正確または限定的であると、環境を理解することが困難になることは間違いありません。
ポリシーの適用は、CMDBまたはその他の情報リポジトリの正確性または完全性によって制限されるべきではありません。名前付けに一貫性がない場合は、これを回避する方法があるはずです。
CMDB を持っていない人にとっては、もっと単純なものを使用しても問題はありません。たとえば、ほとんどのシステムでは、 でデータをインポートおよびエクスポートできます。CSV 形式で、データを管理するための非常に移植性の高い方法になります。
イルミオがワークロードのラベル付けを簡素化および自動化する方法
イルミオは、ゼロトラストセグメンテーションポリシーの命名と適用のプロセスを根本的に簡素化するシンプルなツールセットを開発しました。ツールを持つことは解決策の一部であり、それらを正しく適用することが違いを生むと言わざるを得ません。
ゼロトラストを実装するための鍵は一貫性です。構造化された命名スキームにより、セキュリティポリシーは異なる環境(さまざまな ハイパーバイザー やクラウドなど)間で移植可能になります。
たとえば、IP アドレス モデルは常に同じであるため、機能します。ネットワークに接続されているすべてのデバイスは、AAA の形式を想定しています。BBB。CCC.DDD/XXです。これがなければ、私たちはいかなる形のコミュニケーションも持たないでしょう。ワークロードのラベル付けについても同じことが言えます。一線性のあるモデルがないと、組織のセキュリティが損なわれる可能性があります。
Illumioは、いくつかの簡単な手順で命名プロセスを合理化します。
- ステップ1: すべての組織には、CMDB、スプレッドシート、タグのリスト(またはこれらすべての組み合わせ)など、独自の「信頼できる情報源」があります。完全に正確であるとは思えなくても、イルミオは各ワークロードからメタデータを収集し、ネットワークとワークロードからデータを自動的に更新できます。
- ステップ2: ネットワークからの情報を使用します。たとえば、運用サーバーは、開発サーバーとは異なるサブネットに存在する可能性があります。IP アドレスを使用してルールの作成を開始することは現実的ではありませんが、ネットワーク情報は名前を生成するための適切な出発点となります。
- ステップ3: ホスト名を使用します。時間の経過とともに不整合が蓄積されている可能性がありますが、文字列の一貫した部分を特定し、できるだけ多くのワークロードでそれを解析することで、ギャップを埋めることができます。この情報は、ほとんどすべてのソースから得ることができます。
ここまで、既存の信頼できる情報源を取得し、潜在的な環境を検出し、Web やデータベースなどのサーバーの役割を強調表示できるホスト名情報を特定しました。
これらの手順を完了すると、トラフィック フロー情報を使用して、他の手順に欠けている可能性のあるコア サービスやその他の機能について学習し、特定できます。これは、未知のサーバーを特定するのに役立ちますが、重要なサーバー。
これらすべての知識があれば、各ワークロードにラベルを簡単に適用でき、それを使用してワークロード間の通信を視覚化し、ゼロトラストセグメンテーションポリシーを適用できます。
構造化されたラベル付けを使用すると、環境のマップは次のようになります。

ワークロードにラベルを付けるプロセスが簡単であればあるほど、マップはシンプルになり、セグメンテーションから真の価値をより迅速に得ることができます。
もちろん、これらの手順は任意の順序で実行できます。一部のベンダーは、トラフィック学習を最初のステップとして位置づけます。ここでの課題は、認識されたポートで多数のフローを生成しているという理由だけで、通信が正当に見える可能性があることです。その結果、結果の潜在的な不正確さを元に戻すのに長い時間がかかる場合があります。これにより、マップのクリーンアップに時間がかかるため、値に到達するプロセスが遅くなります。固定情報を最初に使用する方がはるかに簡単で安全です。
Illumio Coreのシンプルなツールを使用すると、必要なデータを簡単に収集し、ラベリングのプロセスを自動化できます。このアプローチにより、データの不足や、セキュリティポリシーの特定と展開における潜在的な複雑さに関する懸念が解消されます。
詳細については:
- マイクロセグメンテーションのラベリングを簡素化するための5つのヒントをお読みください。
- ゼロトラストセグメンテーションに対するイルミオのアプローチの詳細については、 イルミオコアの概要 をダウンロードしてください。